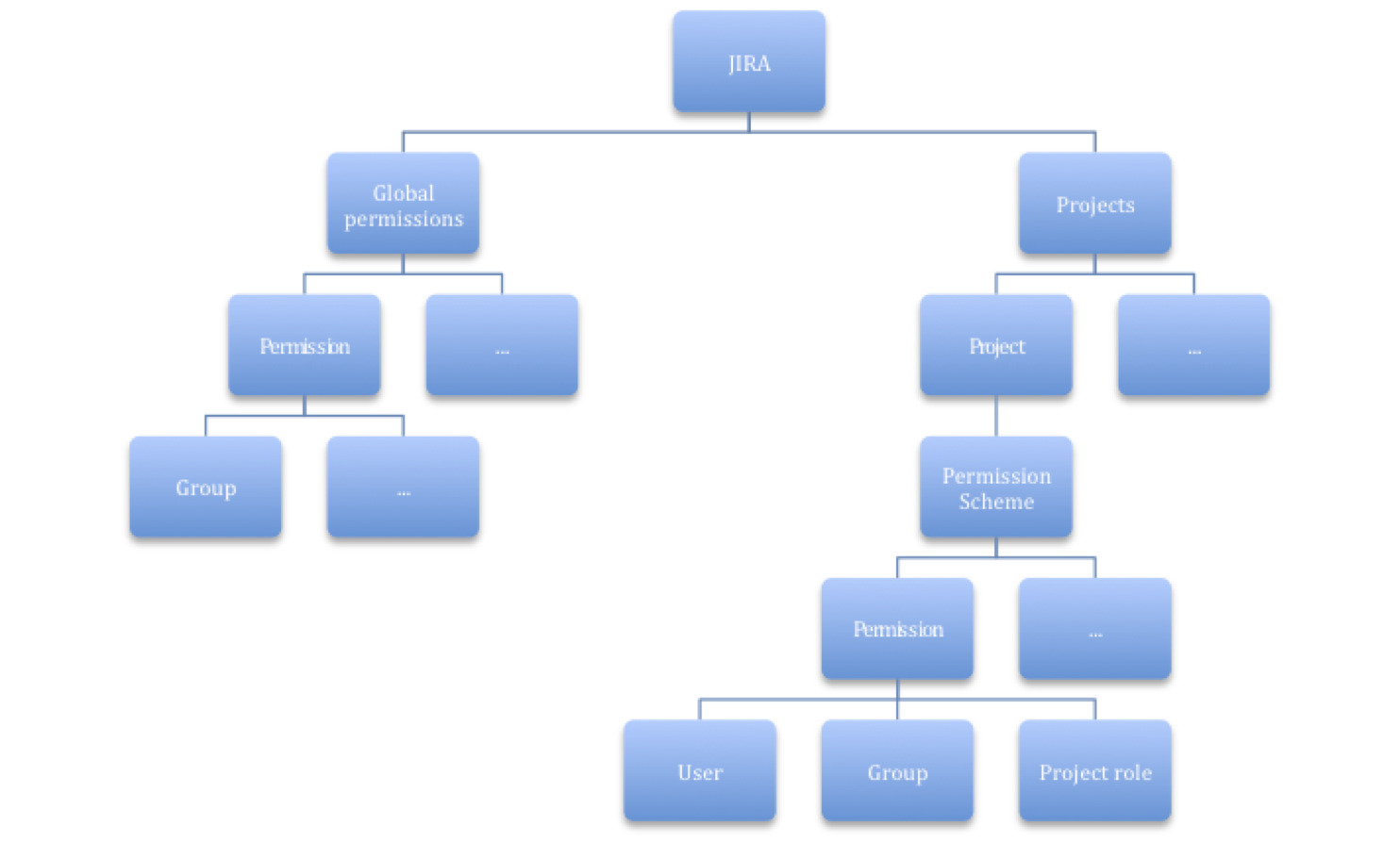
In the first part of this tutorial we learnt the importance of JIRA schemes and how to configure some of them:
- Issue type scheme.
- Issue type screen scheme.
- Field configuration scheme.
- Screen scheme.
In the second part of this tutorial we'll discover other types of schemes that JIRA provides to fine tune our projects:
- Permission scheme.
- Issue security scheme.
In this part we'll discover what workflow schemes and notification schemes are and how to use them.
Workflow Scheme
A workflow scheme let an administrator establish a relation between an issue type and a workflow and it has got a special entry to assign a workflow to all unmapped issue types as well.
What A Workflow Is
The concept of workflow is central in JIRA and it's where most of JIRA power resides in. Let's start with an example: in your project you define a couple of custom issue type called risk and documentation. So far they're just a name: a moniker that helps you categorize your projects issues into named sets but with no additional value. The next thing you'd probably do is to define custom fields for the new issue types of your projects to store the additional data you might need (such as a document author, a document title and so forth.)
As soon as you start using the new issue types in your project you'll realize (or your users will do) that it's not very intuitive to open, resolve and close a document (or a risk). Moreover, users will start complain that some operations are missing: reviewing a documentation, escalating a risk, etc.
JIRA workflows solve this problem: they let you define the process which an issue (of a specific type) will go through. The process is modeled as a finite state machine with transitions between state where you can even hook security policies and business rules (conditions and validators).
Additionally, JIRA will let you specify other information that will let you glue together the features that JIRA offers (such as screens) to fine tune your project and provide your users the interface they expect.
A Use Case
For the sake of simplicity we'll start with a very simple example. Let's suppose that you've got a dependency with a third party that, sometimes, takes charge of an issue for part of its lifetime: it might be, for example, the software quality assurance department of your organization to which your code changes are submitted for validation. Then, you might want to put issues in a waiting state to explicitly reflect this fact.
A goot starting point to implement this custom workflow is copying the default JIRA workflow and using it as a starting point. The modifications you'll need to apply to the default state machine are:
- Create a new state: Waiting for feedback.
- Create new transitions to the new state:
- Ask feedback transition from the In Progress state to the Waiting for feedback state.
- Create new transitions from the new state:
- Continue transition from the Waiting for feedback state to the In Progress state.
- Resolve Issue transition from the Waiting for feedback state to the Resolved state.
- Close Issue transition from the Waiting for feedback state to the Closed state.
Screens for Transition Views
When you toggle the state of an issue, you can assign the transition a screen that will be presented to the user. You can choose one of the bundled JIRA screens or create a screen of your own. If during a transition you want the user to input some additional data, a transition screen is the place where you can ask the user to do so.
For the new Resolve Issue transition, for example, I replicate the settings in the default JIRA workflow Resolve Issue transition, that is using the Resolve Issue Screen during the transition.
Conditions
Conditions are propositions that must hold for the transition to complete successfully. Conditions, for example, are often used to create a security policy for a workflow transition. Some of the conditions that JIRA offers are:
- Only assignee
- Only reporter
- Permission
- User is in group
- User is in project role
- User is in group custom field
In this use case, for example, we want the Ask feedback and Continue transitions to be initiated only by the current assignee of an issue.
In the case of the Close Issue and Resolve Issue transitions, we replicated the conditions on the corresponding default JIRA workflow transitions, that is, check if the user has got the Close Issue permission or the Resolve Issue permission.
How To Create a Workflow
To create a workflow you've got to:
- Define the state machine for you workflow.
- Create a new workflow or copy an existing workflow that could be used as a starting point.
- Implement the state machine adding all the states you defined and all the possible transitions between the states.
- Optionally define and assign the screens you need to display during the workflow transitions.
- Define the conditions that must hold for a each transition to complete: pay attention to take into account JIRA standard permissions (such as the Close Issue and Resolve Issue) in the conditions for your transitions.
How To Create a Workflow Scheme
Before creating a workflow scheme, all of the required workflows for the issue types you're going to manage in a specific project must have been prepared. To create a workflow scheme, you've got to:
- Create a new workflow scheme.
- Assign the default workflow to be used for unmapped issue types.
- Assign a workflow to every issue type whose state machine you want to modify in the current scheme.
Apply the workflow to a project and the modification will take effect.
Please note that changing the workflows that are used in a project with existing issues is a potentially disruptive task that must be performed with care. Changing the workflow for an issue type might require mapping existing issues that find themselves in states that are no longer valid to valid states of the new workflow. JIRA will detect such conflicts and will ask the administrator to establish these mappings when changing a workflow or a workflow scheme for a project.
Best Practices
Hopefully, JIRA won't even let you modify the default system workflow (unless you hack it). Different projects usually mean different users and, although the words we use might be the same, the meaning we give them might differ a lot so the recommendation is the same: always create a custom scheme for your project when in doubt. It's easier to consolidate multiple equivalent schemes into one than decoupling projects that share schemes that were supposed to never change. JIRA lets you copy many of the objects it manages including workflow and workflow schemes.
Notification Schemes
JIRA can notify users when some event has happened. The notification scheme establishes a relation between the type of event and the users who will receive a notification.

Event Types
Some of the types of event that JIRA offers are:
- Issue Created.
- Issue Resolved.
- Issue Closed.
- Work Logged On Issue.
The complete list can be checked in the official JIRA documentation. JIRA also offers a Generic Event that can be fired, for example, from a workflow transition, that can be used to extend the set of JIRA events should you need a new one.
Users Who Can Receive Notifications
The identities whom JIRA lets you send notification to are:
- Current Assignee.
- Reporter.
- Current User.
- Project Lead.
- Component Lead.
- Single User (chosen from a list).
- Group (chosen from a list).
- Project role (chosen from a list).
- Single email address (input by the user).
- All Watchers.
- User from a custom field.
- Group from a custom field.
A Use Case
Let's suppose that you're a project or a component leader and you want to receive a notification every time an issue is resolved or closed: it will be sufficient to create a custom scheme, for example by copying JIRA default notification scheme, and adding a notification for the desired event to the appropriate receiving identity.
How To Create a Notification Scheme
To create a notification scheme it's necessary to perform the following operations:
- Create a new notification scheme or copy an existing one to use it as a starting point.
- For every event you wish to handle, add a notification and assign the set of receiving identities.
A notification scheme can be associated to a project and it will take effect immediately.